

ESET researchers recently described Wslink, a unique and previously undocumented malicious loader that runs as a server and that features a virtual-machine-based obfuscator. There are no code, functionality or operational similarities that suggest this is likely to be a tool from a known threat actor.
In our white paper, linked below, we describe the structure of the virtual machine used in samples of Wslink and suggest a possible approach to see through the obfuscation techniques used in the analyzed samples. We demonstrate our approach on chunks of code of the protected sample. We were not motivated to fully deobfuscate the code, because we discovered a non-obfuscated sample.

Obfuscation techniques are a kind of software protection intended to make code hard to understand and hence conceal its objectives; obfuscating virtual machine techniques have become widely misused for illicit purposes such as obfuscation of malware samples, since they hinder both analysis and detection. The ability to analyze malicious code and subsequently improve our detection capabilities is the driving force behind our motivation to overcome these techniques.
Virtualized Wslink samples do not contain any clear artifacts, such as specific section names, that easily link it to a known virtualization obfuscator. During our research, we were able to successfully design and implement a semiautomatic solution capable of significantly facilitating analysis of the underlying program’s code.
This virtual machine introduced a diverse arsenal of obfuscation techniques, which we were able to overcome to reveal a part of the deobfuscated malicious code that we describe in this blogpost. In the last sections of our white paper, we present parts of the code we developed to facilitate our research.
Our white paper also provides an overview of the internal structure of virtual machines in general, and introduces some important terms and frameworks used in our detailed analysis of the Wslink virtual machine.
In an earlier white paper, we described the structure of a custom virtual machine, along with our techniques to devirtualize the machine. That virtual machine contained an interesting anti-disassembly trick, previously utilized by FinFisher – spyware with extensive spying capabilities, such as live surveillance through webcams and microphones, keylogging, and exfiltration of files. We additionally presented an approach for its deobfuscation.
This blogpost consists of excerpts from the Under the hood of Wslink’s multilayered virtual machine white paper; we encourage everyone interested in virtual machines and obfuscation techniques to go through the original white paper, as it contains detailed information on various steps required to see through the obfuscation techniques used in Wslink.
Overview of virtual machine structures
Before diving into the analysis of Wslink’s virtual machine (VM), we provide an overview of the internal structure of virtual machines in general, describe known approaches to deal with such obfuscation, and introduce some important terms and frameworks used in our detailed analysis of the Wslink VM.
General structure of virtual machines
Virtual machines can be divided into two main categories:
- System virtual machines – support execution of complete operating systems (e.g., various VMWare products, VirtualBox)
- Process virtual machines – execute individual programs in an OS-independent environment (e.g., Java, the .NET Common Language Runtime)
Here, we are interested only in the second category – process virtual machines – and we will briefly describe certain parts of their internal anatomy necessary to understand the rest of this paper.
Process virtual machines run as normal applications on their host OSes, and in turn run programs whose code is stored as OS-independent bytecode (Figure 1) that represents a series of instructions – an application – of a virtual instruction set architecture (ISA).

Figure 1. Illustration of bytecode, where all opcodes and operands are virtual
One can also think about bytecode as a sort of intermediate representation (IR); an abstract representation of code consisting of a specific instruction set that resembles assembly more than a high-level language. It is also known as intermediate language.
The use of IR is convenient in terms of code reusability – when one needs to add support for a new architecture or CPU instruction set, it is easier to convert it to the IR instead of writing all the required algorithms again. Another benefit is that it can simplify the application of some optimization algorithms.
One can generally translate both high- and low-level languages into an IR. Translation of a higher-level language is known as “lowering”, and similarly translation of a lower-level one, “lifting”.
The following example lifts an assembly block bb0 into a block with the pseudo-IR code irb0. All assembly instructions are translated into a set of IR operations and individual operations in sets do not affect each other, where ZF stands for zero flag and CF for carry flag:
bb0:
MOV R8, 0x05
SUB AX, DX
XCHG ECX, EDX
irb0:
R8 = 0x05
EAX[:0x10] = EAX[:0x10] – EDX[:0x10]
ZF = EAX[:0x10] – EDX[:0x10] == 0x00
CF = EAX[:0x10] < EDX[:0x10]
...
ECX = EDX
EDX = ECX
Modern process VMs usually provide a compiler that can lower code written in a high-level language -- one that is easy to understand and comfortable to use – into the respective bytecode.
A VM’s ISA generally defines the supported instructions, data types and registers, among other things, that naturally must be implemented by a virtual ISA as well.
Instructions consist of the following parts:
- opcodes – operation codes that specify an instruction
- operands – parameters of the instructions
ISAs often use two well-known virtual registers:
- virtual program counter (VPC) – a pointer to the current position in the bytecode
- virtual stack pointer – a pointer to pre-allocated virtual stack space used internally by the VM
The virtual stack pointer does not have to be present in all VMs; it is common only in a certain type of VM – stack-based ones.
We will refer to the instructions and their respective parts of a virtual ISA simply as virtual instructions, virtual opcodes, and virtual operands. We sometimes omit the explicit use of “virtual” when it is obvious that we are talking about the virtual representation.
An OS-dependent (Figure 2) executable file – interpreter – processes the supplied bytecode and sequentially interprets the underlying virtual instructions thus executing the virtualized program.

Figure 2. Illustration of the relationship between bytecode and the VM’s interpreter
Transfer of control from one virtual instruction to the next during interpretation needs to be performed by every VM. This process is generally known as dispatching. There are several documented dispatch techniques such as:
- Switch Dispatch – the simplest dispatch mechanism where virtual instructions are defined as case clauses and a virtual opcode is used as the test expression (Figure 3)
- Direct Call Threading – virtual instructions are defined as functions and virtual opcodes contain addresses of these functions
- Direct Threading – virtual instructions are defined as functions again; however, in comparison to Direct Call Threading, addresses of the functions are stored in a table and virtual opcodes represent offsets to this table. Each function should indirectly call the following one according to the specification (Figure 4)
The body of a virtual opcode in the interpreter’s code is usually called a virtual handler because it defines the behavior of the opcode and handles it when the virtual program counter points to a location in the bytecode that contains a virtual instruction with that opcode.
By context, regarding VMs, we mean a sort of virtual process context: each time a process is removed from access to the processor during process switching, sufficient information on its current operating state – its context – must be stored such that when it is again scheduled to run on the processor, it can resume its operation from an identical position.
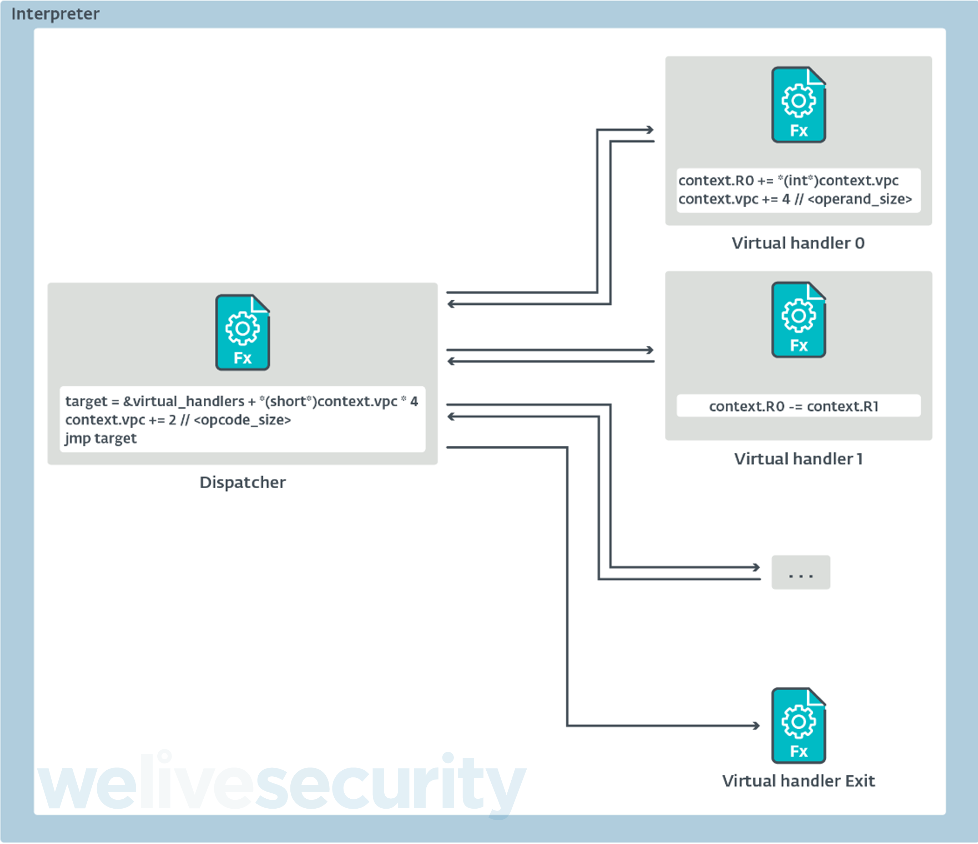
Figure 3. Illustration of Switch Dispatch, where R0 is a virtual register

Figure 4. Illustration of Direct Threading
Obfuscation techniques are a kind of software protection intended to make code hard to understand and hence conceal its objectives. Such techniques were initially developed to protect the intellectual property of legitimate software, e.g., to hamper reverse engineering.
Virtual machines used as obfuscation engines are based on process virtual machines, as described above. The primary difference is that they are not intended to run cross-platform applications and they usually take machine code compiled or assembled for a known ISA, disassemble it, and translate that to their own virtual ISA. It is also usually the case that the VM environment and the virtualized application code are contained all in one application, whereas traditional process VMs usually consist of a process that runs as a standalone application that loads separate, virtualized applications.
The strength of this obfuscation technique resides in the fact that the ISA of the VM is unknown to any prospective reverse engineer – a thorough analysis of the VM, which can be very time-consuming, is required to understand the meaning of the virtual instructions and other structures of the VM. Further, if performance is not an issue, the VM’s ISA can be designed to be arbitrarily complex, slowing its execution of virtualized applications, but making reverse engineering even more complex. Understanding of the VM is necessary for decoding the bytecode and making the virtualized code understandable.
Context has a bit of a different meaning in regard to obfuscating virtual machines: each time we want to switch from the native to virtual ISA or vice-versa, sufficient information – context – on the current operating state must be stored so that when the lSA has to be switched back, execution can resume with only the relevant data and registers modified.
Additionally, obfuscating VMs usually virtualize only certain “interesting” functions – native context is mapped to the virtual one and bytecode, representing the respective function, is chosen beforehand. The built-in interpreter is invoked afterwards (Figure 5). Beginnings of the original functions contain code that prepares and executes the interpreter – entry of the VM (vm_entry); the rest of their code is omitted in Figure 5.
Interpreter, bytecode, and virtual ISA code with data of obfuscating VMs are often all stored in a dedicated section of the executable binary, along with the rest of the partially virtualized program.
Figure 5 shows the way a function, Function 1, in the original application targeting a common ISA, can be virtualized for an obfuscating VM’s ISA. It needs to be converted into bytecode, for example using a generate_bytecode method. Its body is afterwards overwritten by a call into vm_entry and zeroes. The vm_entry function chooses the respective bytecode, for example, based on the calling function’s address, then conducts a context switch, and next interprets the bytecode. Finally, it returns to the code where the virtualized function, Function 1, would return.

Figure 5. Overview of the virtualization process
In VMs hosted on x86 architectures, such context switches usually consist of a series of PUSH and POP instructions. For example:
PUSH EAX
PUSH EBX
PUSH ECX
...
MOV ECX, context_addr
POP DWORD PTR [ECX]
POP DWORD PTR [ECX + 4]
POP DWORD PTR [ECX + 8]
...
When the bytecode is fully processed, virtual context is mapped back to native context and execution continues in the non-virtualized code; however, another virtualized function could be executed in the same manner, right away.
Note that several context switches can occur in one virtualized function, for example when a native instruction from the original ISA could not be translated to virtual instructions or an unknown function from the native API needs to be executed.
Wslink’s virtual machine entry – vm_entry
Let's get to the analysis of Wslink’s VM now. There are several function calls that enter the VM, all of which are followed by some gibberish data that IDA attempts to disassemble – the data most likely just overwrites the function’s original code before virtualization (Figure 6).

Figure 6. Entry point to the virtual machine
The vm_entry of the VM:
- calculates the actual base address by subtracting the expected relative virtual address from the actual virtual address of a place in the code
- unpacks code and data related to the VM on the first run; it uses the calculated base address to determine the location of the packed VM and destination of the unpacked data
- executes an initialization function – one of the vm_pre_init() functions to be described is based on the caller’s relative address that is mapped to the respective vm_pre_init()
Packer
Wslink’s VM is packed with NsPack to reduce the size of the huge executable file; additional obfuscation is probably just a side effect. Similarities between Wslink’s unpacking code and ClamAV’s unspack() function are clearly visible (Figure 7 and Figure 8). Note that Ghidra has optimized out calculation of the base address.

Figure 7. A part of vm_entry of the virtual machine decompiled with Ghidra

Figure 8. Function used to unpack NsPack in ClamAV
The vm_pre_init_dispatch_table in Figure 7 is the structure that maps callers’ addresses of the vm_entry to the respective vm_pre_init() functions that are to be described.
Virtual machine initialization
Initialization of the VM consists of several steps, such as saving values of the native registers on the stack and later moving them to the virtual context, relocation of its internal structures, or preparation of bytecode. We cover these steps more thoroughly in the following subsections.
vm_pre_init() functions
vm_pre_init() functions are meant only to prepare parameters for another stage of initialization (Figure 9). These functions call a single vm_init() function (explained in the next section) with specific parameters. The supplied parameters are:
- CPU flags, which are stored on the stack with a PUSHF instruction at the beginning of each function
- hardcoded offset to a virtual instruction table that represents the first virtual instruction to be executed (its opcode)
- hardcoded address of the bytecode to be interpreted
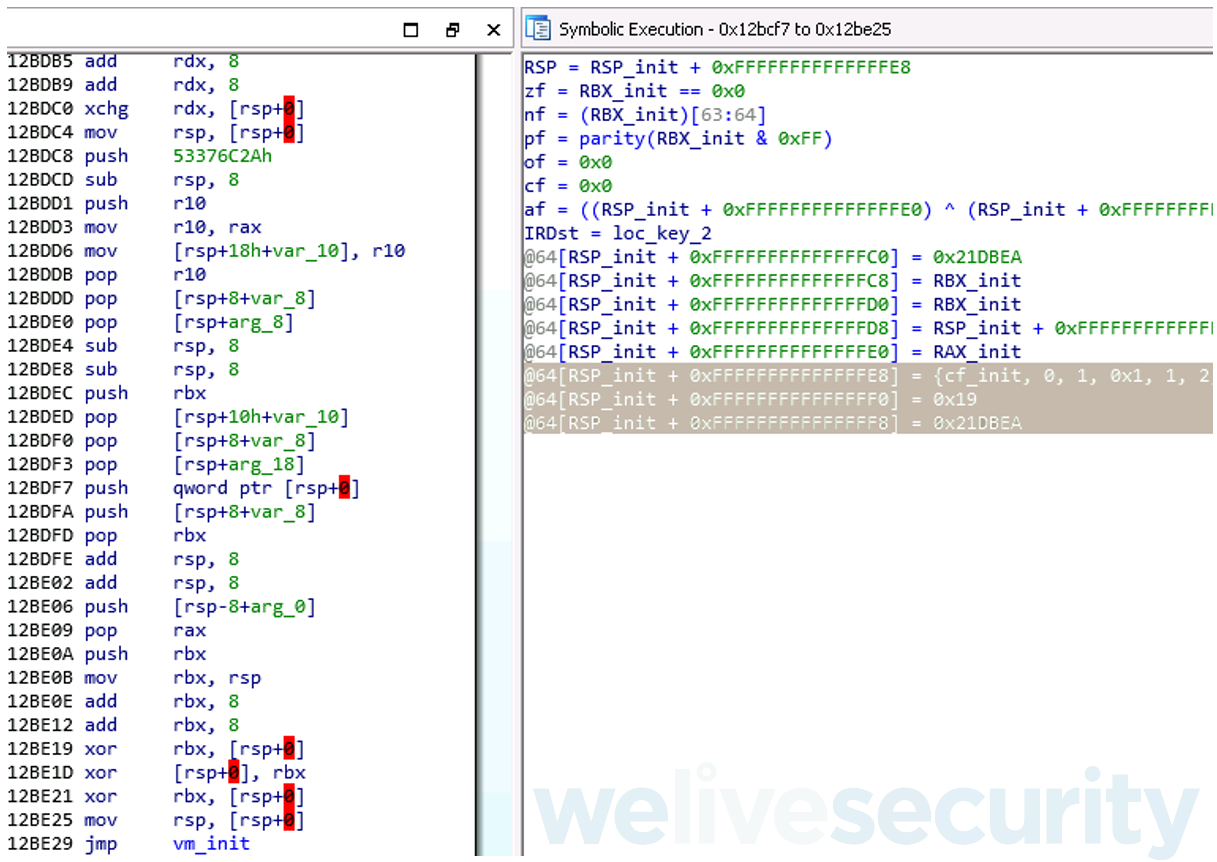
Figure 9. Miasm’s symbolic execution of a vm_pre_init() showing parameters supplied to vm_init()
vm_init() function
vm_init() pushes all the native registers and the supplied CPU flags from parameters (context) onto the stack. The native context will later be moved to the virtual one that, in addition, holds several internal registers.
One of the internal registers determines whether another instance of the VM is already running – there is only one global virtual context and only one instance of the VM can run at a time. Figure 10 shows the part of the code busy-waiting for the virtual register, where RBP contains the address of the virtual context and RBX the offset of the virtual register – the internal register is stored in [RBX + RBP].
The entire function is summarized in Figure 11.
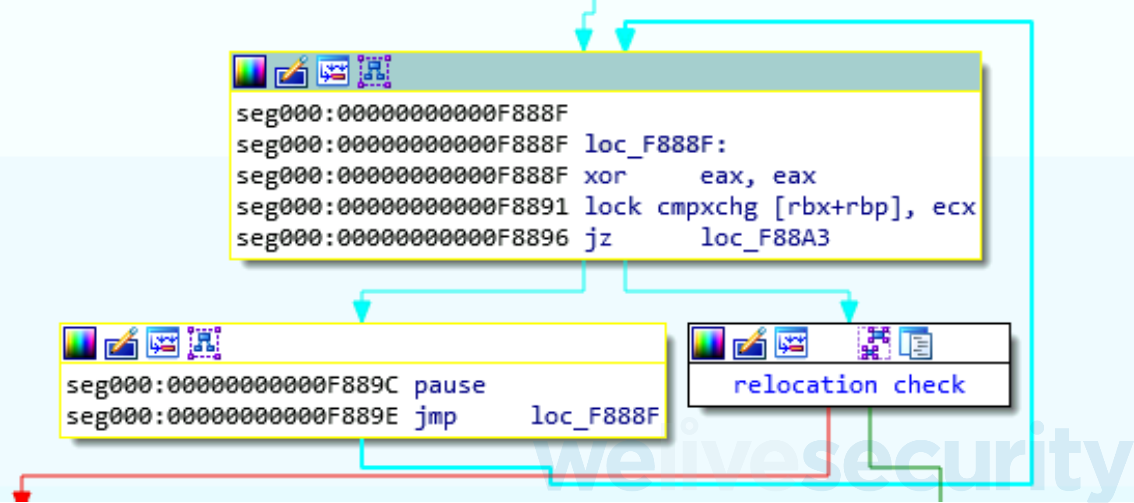
Figure 10. Busy-waiting for interpreter in vm_init()
The bytecode’s address, supplied in the parameters, is added to the virtual context along with the address of the virtual instruction table, which is hardcoded. Both have a dedicated virtual register.
The VM calculates the base address again in the same way as was described for vm_entry; in addition, it stores the address in another internal register that is used later, should an API be called. Then the base address is used to relocate the instruction table, its entries, and the bytecode’s address.
The calculated base address is simply added to all the function addresses if they have not already been relocated.
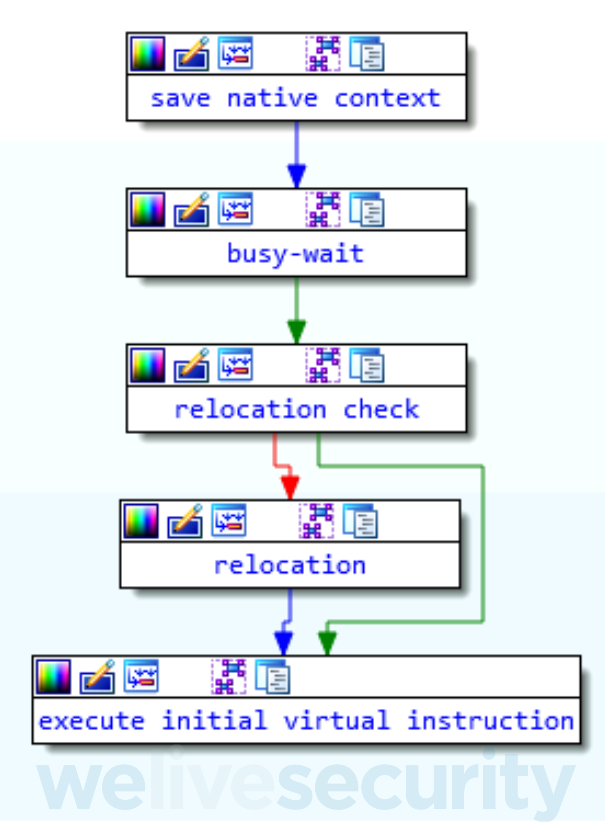
Figure 11. vm_init() summary
Virtual instructions of the second virtual machine
We start by looking at the first few executed virtual instructions to observe the behavior of the second VM and then try to process the rest of them in a partially automated way.
The diagram in Figure 12 highlights in blue where the virtual instructions of the second VM are in the structure of the VMs.

Figure 12. Virtual instructions in the structure of the virtual machines
The first virtual instruction
The first virtual instruction is, exceptionally, not obfuscated, as can be seen in Figure 13. Finally, we can see some operations in the virtual context.
By inspecting the modified memory and calculated destination address of the instruction, it is clear that the instruction does three things:
- Zeroes out a virtual 32-bit register at offset 0xB5 in the virtual context (highlighted in gray in Figure 13), which is stored in the RBP register
- A virtual 64-bit register at offset 0x28 is increased by 0x04: it is the pointer to the bytecode – virtual program counter. The size of the virtual instruction is hence four bytes (highlighted in red in Figure 13).
- The next virtual instruction is prepared to be executed, the offset to the virtual instruction table – virtual opcode – is fetched from the virtual program counter. The virtual instruction table is at offset 0xA4 (highlighted in green in Figure 13). This means that the VM uses the Direct Threading Dispatch technique.

Figure 13. The initial virtual instruction of the second VM
Note that the size of the next instruction’s opcode is only two bytes and the remaining word is left unused. We can see that it is just a zero when we look at virtual operands (Figure 14). Sizes of the other instructions differ – it is not just padding that preserves the same size for all instructions.
Figure 14. Bytecode of the virtual instruction
The second virtual instruction
The second virtual instruction does not do anything special; it just zeroes out several virtual registers and jumps to the next instruction (Figure 15).

Figure 15. Destination address and memory modified by the second virtual instruction
The third virtual instruction
The third virtual instruction stores the address of the stack pointer in a virtual register (Figure 16); the offset of the register is determined by one of the operands, and its offset is 0x0141 in our case.

Figure 16. Destination address and memory modified by the third virtual instruction
The fourth virtual instruction
The fourth instruction contains two immediately visible anomalies in comparison with previous instructions – the stack pointer’s delta is lower at the end of the function and it contains a conditional branch (Figure 17).
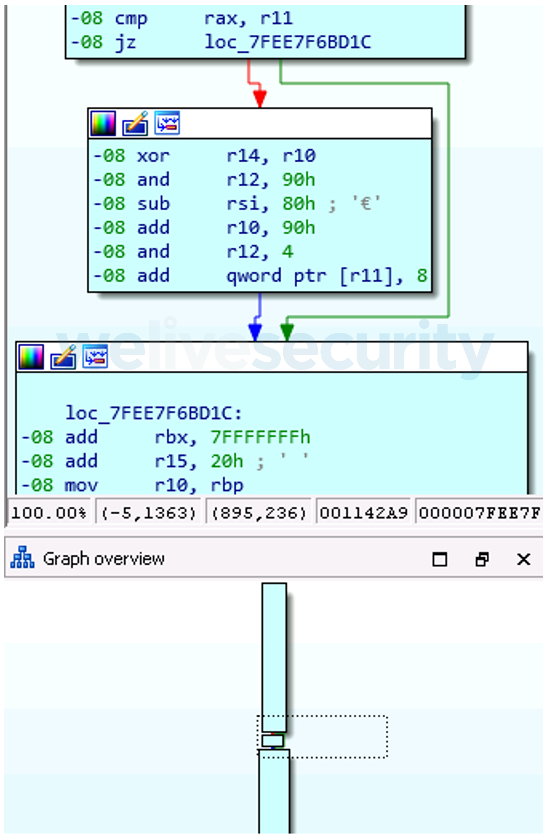
Figure 17. The conditional branch and delta of the stack pointer of the fourth virtual instruction
Symbolic execution of the first block reveals that a value is popped from the stack into a virtual register (Figure 18), which makes sense as the values of the native registers remain on the stack after being saved there by vm2_init(). They are now being moved to the virtual context – the context switch is partially performed by a number of virtual instructions, each of which pops one value off the stack into a different register.
Figure 18. Destination address and memory modified by the fourth virtual instruction
The virtual register, where the value of the native register is to be saved, is determined by an operand and two other virtual registers at offsets 0x0B and 0x70. However, their initial value is already known: they were set to zero by the second virtual instruction (Figure 15), which means that we can calculate the offset of the register and simplify the expressions – they are used just to obfuscate the code.
Rolling decryption
Analysis of other virtual instructions confirmed that the virtual registers at offsets 0x0B and 0x70 are meant just to encode operands. This technique is called rolling decryption and it is known to be used by the VMProtect obfuscator. However, it is the only overlap with that obfuscator and we are highly confident that this VM is different.
The obfuscation technique is certainly one of the reasons for the enormous number of virtual instructions – use of the technique requires duplication of individual instructions since each uses a different key to decode the operands.
Simplification
The expressions can be simplified to the following when we apply the known values of the virtual registers:
IRDst = (-@16[@64[RBP_init + 0x28] + 0x4] ^ 0x3038 == @16[@64[RBP_init + 0x28] + 0x6])?(0x7FEC91ABD1C,0x7FEC91ABCF6)
@64[RBP_init + {-@16[@64[RBP_init + 0x28] + 0x4] ^ 0x3038, 0, 16, 0x0, 16, 64}] = @64[RSP_init]
Now let us take a look at the expression in the conditional block:
@64[RBP_init + {@16[@64[RBP_init + 0x28] + 0x6], 0, 16, 0x0, 16, 64}] = @64[RBP_init + {@16[@64[RBP_init + 0x28] + 0x6], 0, 16, 0x0, 16, 64}] + 0x8
We can now see that the virtual instruction is definitely POP – it moves a value off the top of the stack to a virtual register, whose offset is still obfuscated with a simple XOR; it additionally increases the stack pointer when the destination register is not the stack pointer.
As values in the bytecode are known too, we can apply them and simplify the instruction even further into the following final unconditional expressions:
IRDst = @64[@64[RBP_init + 0xA4] + 0x5A8]
@64[RBP_init + 0x28] = @64[RBP_init + 0x28] + 0x8
@64[RBP_init + 0x141] = @64[RBP_init + 0x141] + 0x8
@64[RBP_init + 0x12A] = @64[RSP_init]
Automating analysis of the virtual instructions
As doing this for more than 1000 instructions would be very time consuming, we wrote a Python script with Miasm that collects this information for us so we can get a better overview of what is going on. We are particularly interested in modified memory and destination addresses.
Just as in the fourth virtual instruction, we will treat certain virtual registers as concrete values to retrieve clear expressions. These registers are dedicated to the rolling decryption and perform memory accesses that are relative to the bytecode pointer, e.g., [<obf_reg_1>] = [<bytecode_ptr> + 0x05] ^ 0xABCD.
Subsequently we concretize the pointer to the virtual instruction table too and, by the end of the virtual instruction: calculate addresses of the next ones, clear the symbolic state, and start with the following virtual instructions.
We additionally save aside memory assignments that are not related to the internal registers of the VM and gradually build a graph based on the virtual program counter (Figure 19).
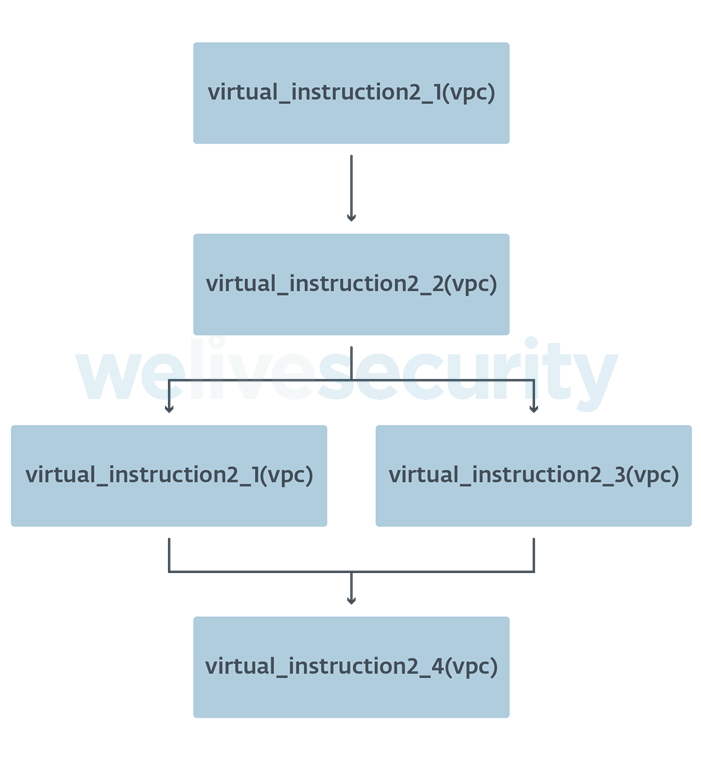
Figure 19. Call graph generated from memory assignments and the VPC
We stop when we cannot unambiguously determine the next virtual instructions to be executed; one can automatically process most of the virtual instructions in this way.
Note that instructions featuring complex loops cannot be processed with certainty and need to be addressed individually due to the path explosion problem of symbolic execution, which is described for example in the paper Demand-Driven Compositional Symbolic Execution: “Systematically executing symbolically all feasible program paths does not scale to large programs. Indeed, the number of feasible paths can be exponential in the program size, or even infinite in presence of loops with unbounded number of iterations.”
For other actions related to virtual instructions and virtual machine initialization, please consult the ESET Research white paper Under the hood of Wslink’s multilayered virtual machine.
Conclusion
We have described internals of an advanced multilayered virtual machine featured in Wslink and successfully designed and implemented a semiautomatic solution capable of significantly facilitating analysis of the program’s code.
This virtual machine introduced several other obfuscation techniques such as junk code, encoding of virtual operands, duplication of virtual opcodes, opaque predicates, merging of virtual instructions, and a nested virtual machine to further obstruct reverse engineering of the code that it protects, yet we successfully overcame them all.
To deal with the obfuscation, we modified a known technique that extracts the semantics of the virtual opcodes using symbolic execution with simplifying rules. Additionally, we made concrete the internal virtual registers for obfuscation along with memory accesses relative to the virtual program counter to automatically apply known values and de-obfuscate semantics of the virtual instructions – this additionally broke down boundaries between individual virtual instructions.
Boundaries are necessary to prevent path explosion of the symbolic execution; we would lose track of the virtual program counter – our position in the interpreted code – without them.
We defined new boundaries by symbolizing the address of the virtual instruction table, since it is required to get the next instruction, and concretized it only when we needed to move to the following virtual instructions. We subsequently constructed a control flow graph of the original code in an intermediate representation from one of the bytecode blocks based on the virtual program counter, and extracted deobfuscated semantics of individual virtual instructions. We finally extended the approach to process both virtual machines at once by entirely concretizing the nested one. Again: for full details, see our white paper.



